
Compound AI systems, where multiple AI models collaborate to make intelligent decisions and leverage tools, are setting the standard for both academic benchmarks and real-world applications. These systems have demonstrated success in verticals such as law, search, and personalized learning, alongside the rise of platforms like AutoGen, LangChain, Crewai, and DSPy that make building multi-agent systems more accessible.
While the past decade has seen tremendous progress in fine-tuning single AI models, the challenge of fine-tuning compound AI systems remains largely unaddressed. How can we train individual models in a system to collectively achieve ideal system behaviour? This question is at the heart of advancing multi-agent systems to break state-of-the-art performance.
Imagine a simple example: an AI-powered search assistant designed to fulfill user requests. This system might consist of a keyword generator, a filtering module, a summarizer, and a response generation model. Feedback on the system’s final output—whether from human evaluators or an LLM as a judge—provides critical signals for improvement. But how do we use this feedback to fine-tune each individual component in the system? Can we backpropagate this feedback across the entire system and achieve SOTA performance using open-source models?
By addressing these questions, we unlock the potential to achieve state-of-the-art results with compound AI systems built entirely on open-source technologies. This approach enables businesses and researchers to develop highly capable, customized systems without relying on proprietary models, bringing SOTA performance within reach for a broader audience.
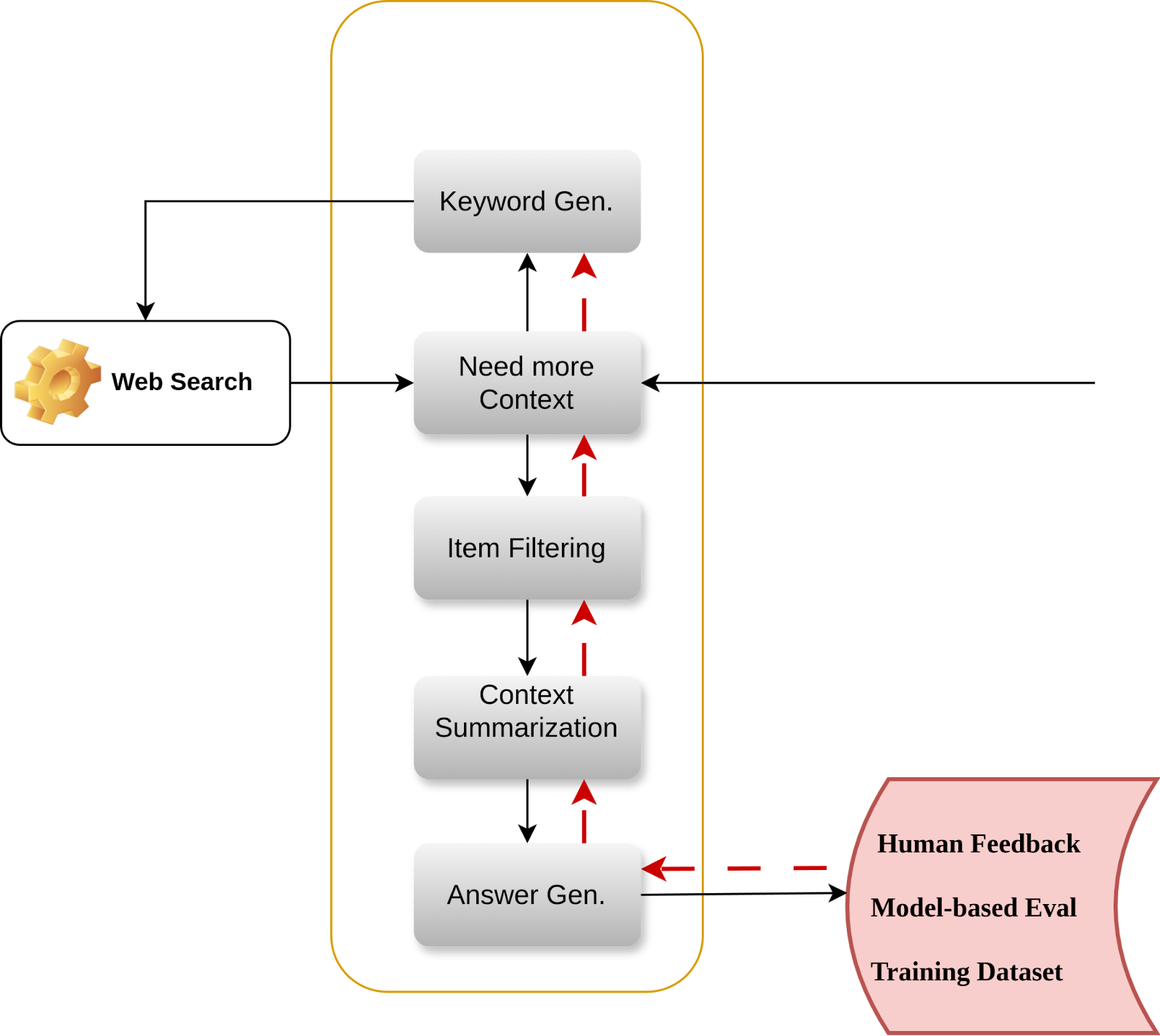
Our End2End Training solution
To solve the challenge of fine-tuning multi-agent systems, we took an innovative approach: building a multi-agent AI system to train multi-agent systems. Our solution focuses on two core tasks:
- Credit Assignment: System-level feedback—whether from human evaluators or LLMs as judges—is translated into actionable feedback for each individual model. For instance, if a search system returns an overly expensive item, the issue might stem from the filter (failing to consider price constraints) or the keyword generator (producing suboptimal queries). Credit assignment pinpoints where improvements are needed.
- Model Fine-Tuning Using Synthetic Data: This feedback is used to generate synthetic data that aligns better with desired outcomes. Individual models are fine-tuned on this data, allowing the compound system to adapt and improve cohesively.
This end-to-end approach enables compound systems to adapt more effectively and supports the development of on-premises solutions tailored to unique customer needs.
Initial Experiments
OpenBook QA Task
We developed a compound AI system for open-domain question answering (openbook QA), leveraging a web search tool. This system includes a keyword generator, a web search tool, and an answer generation model as follows:

Setup: Trained for 3 epochs with a batch size of 3 on 36 samples. At the end of each epoch, individual models fine-tuned for 2 epochs with LoRA using 100 synthetic samples.
Results: Our end-to-end fine-tuning approach significantly improved performance, even surpassing GPT-4o in this task.
| Model in the system | Performance |
| GPT4o | 76 |
| LLama 3.3 70b Instruct | 59 |
| + only prompt optimization (using TextGrad) | 63 |
| + e2e training | 77 |
Big Bench Hard: Word Sorting Task
We evaluated our proposed method on the Big Bench Hard dataset, focusing specifically on the word sorting task, word sorting is a particularly challenging task for state-of-the-art LLMs.
Setup: Trained for 3 epochs with a batch size of 3 on 36 samples. At the end of each epoch, individual models fine-tuned for 2 epochs with LoRA using 100 synthetic samples.
Results: Our approach brought Llama 3.3 70b instruct model’s performance close to GPT-4o’s, demonstrating its competitive effectiveness.
| Models in the system | Performance |
| GPT4o | 85 |
| LLama 3.3 70b instruct | 71 |
| + only prompt optimization (using TextGrad) | 80 |
| + e2e training | 84 |
Why This Matters
These initial results showcase the power of our end-to-end fine-tuning approach for compound AI systems. By leveraging open-source models and systematically fine-tuning them as part of a multi-agent system, we’ve demonstrated that SOTA performance is achievable without reliance on proprietary models.
This solution has broader implications for enterprises seeking highly capable, customizable AI systems, particularly in use cases requiring on-premises deployment or highly specific workflows.
We’d Like to Hear From You
We’re productizing our end-to-end training of compound AI systems and are eager to collaborate with innovators to turn bold ideas into reality.
- Do you have a vision involving complex workflows, challenging reasoning tasks, or on-premises deployment?
We can train SOTA systems and productionize them in weeks. - Let’s Build the Future Together:
Reach out to us at my@leeroo.com. We’d love to hear your ideas and feedback. - Join Leeroo community for further updates: Linkedin, Discord, X.